Slurm测试集群搭建
Slurm测试集群搭建记录
集群搭建目的
由于CoHPC项目计划部署在北大未名二号高性能计算平台上,在开发环节测试,首先自己部署一个Slurm集群。
集群搭建过程
集群规划与机器创建
本次部署计划部署一个master节点(由于仅需要一个测试环境,所以master同时作为管理节点、登录节点和数据传输节点)和四个compute节点。 在北京大学Clab云平台上,创建一台master01机器,2c4g;创建4台compute0[1-4]机器,每一台机器4c8g;全部采用RockyLinux9.5镜像,分配在同一个校园网内网段(pku-new,IPv4 10.129.240.0/20)中。
示例:
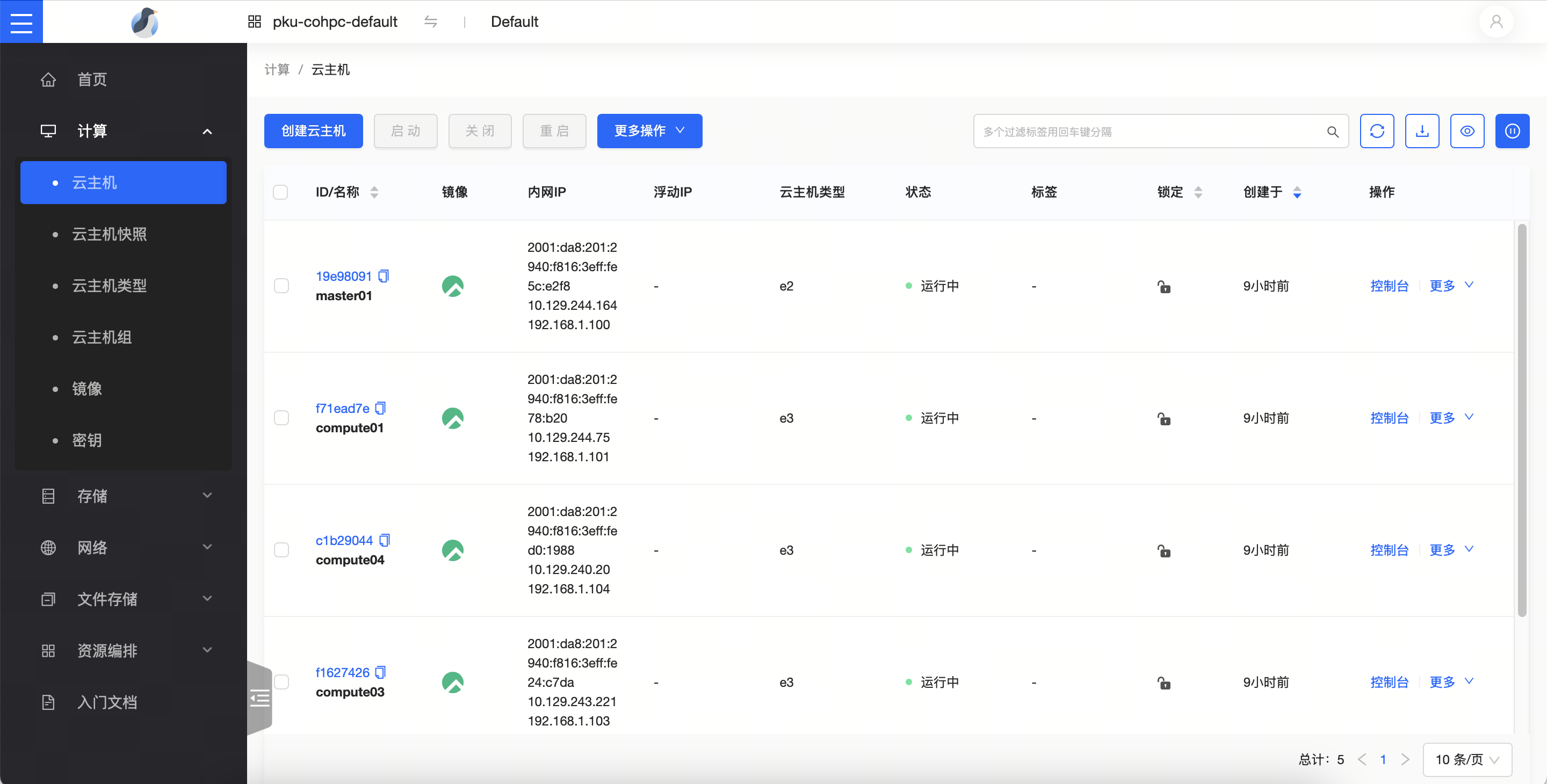
最终我们得到这些机器: 10.129.244.164 master01 10.129.244.75 compute01 10.129.240.45 compute02 10.129.243.221 compute03 10.129.240.20 compute04
机器初始化
在每一台RockyLinux机器上,sudo -i进入root,运行如下脚本来初始化机器环境。
sed -e 's|^mirrorlist=|#mirrorlist=|g' \
-e 's|^#baseurl=http://dl.rockylinux.org/$contentdir|baseurl=https://mirrors.pku.edu.cn/rocky|g' \
-i.bak \
/etc/yum.repos.d/rocky-extras.repo \
/etc/yum.repos.d/rocky.repo
dnf install -y 'dnf-command(config-manager)'
dnf install -y epel-release
dnf config-manager --set-enabled crb
sudo sed -e 's|^metalink=|#metalink=|g' \
-e 's|^#baseurl=https\?://download.fedoraproject.org/pub/epel/|baseurl=https://mirrors.pku.edu.cn/epel/|g' \
-e 's|^#baseurl=https\?://download.example/pub/epel/|baseurl=https://mirrors.pku.edu.cn/epel/|g' \
-i.bak \
/etc/yum.repos.d/epel.repo
dnf update -y
crb enable
dnf install -y vim bash-completion grubby
dnf group install -y "Headless Management" "System Tools" "Development Tools"
grubby --update-kernel ALL --args selinux=0
reboot
这段脚本将完成诸如基本依赖项安装、SELinux禁用等过程。
在各个机器上分别运行以下命令来确认主机名被更改:
hostnamectl set-hostname master01
hostnamectl set-hostname compute01
hostnamectl set-hostname compute02
hostnamectl set-hostname compute03
hostnamectl set-hostname compute04
在每一台机器上,vim /etc/hosts,添加以下内容来完成集群内机器IPv4地址和主机名的映射。
10.129.244.164 master01
10.129.244.75 compute01
10.129.240.45 compute02
10.129.243.221 compute03
10.129.240.20 compute04
机器时间同步
RockyLinux9.5采用chrony工具来完成时间同步,这对于启动Slurm集群重要(Slurm要求集群内机器时间同步)。
vim /etc/chrony.conf以编辑chrony配置。
在master01节点上,做如下修改(不是直接替换掉),配置其采用ntp.pku.edu.cn的授时服务。
# 禁用原有的授时服务
#pool 2.rocky.pool.ntp.org iburst
#sourcedir /run/chrony-dhcp
# 采用新的授时服务
server ntp.pku.edu.cn iburst
# 使得pku-new网络内其他机器可以采用本机器的NTP
allow 10.129.240.0/20
# Serve time
local stratum 10
在诸compute节点上,都做如下修改来采用master01的NTP服务。
# 禁用原有的授时服务
#pool 2.rocky.pool.ntp.org iburst
#sourcedir /run/chrony-dhcp
# 采用新的授时服务
server 10.129.244.164 iburst
在所有节点上都运行
systemctl restart chronyd
systemctl enable chronyd
来采用修改过的配置。
master01节点到其他节点免密登录
在master01节点上生成一个无pass phrase的密钥。
由于Clab上机器登录使用rocky用户,而我们进行配置时采用sudo -i切换到了root用户,该用户下.ssh应该还没有任何密钥对。直接键入ssh-keygen,然后一直按回车即可。
复制公钥:
cat /root/.ssh/id_rsa.pub # 如果不是rsa,这个名字需要改变一下
在compute诸节点上,将该公钥添加进入/root/.ssh/authorized_keys。
然后应当可以从master01节点免密登录至诸计算节点。
ssh compute01
ssh compute02
ssh compute03
ssh compute04
NFS安装和配置
集群需要一个共享文件系统。采用NFS来配置。
服务端:master01
安装NFS、RPC服务
yum install -y nfs-utils rpcbind
创建共享目录
mkdir /data
chmod 755 /data
键入vim /etc/exports并在文件中添加如下内容:
/data *(rw,sync,insecure,no_subtree_check,no_root_squash)
启动RPC和NFS服务
systemctl start rpcbind
systemctl start nfs-server
systemctl enable rpcbind
systemctl enable nfs-server
查看服务端是否正常加载配置文件
showmount -e localhost
# 有如下输出
Export list for localhost:
/data *
客户端:诸compute节点都运行
安装NFS客户端nfs-utils
yum install nfs-utils -y
查看服务端可共享的目录
# manage01 为NFS服务端IP
showmount -e master01
# 有如下输出
Export list for master01:
/data *
挂载服务端共享目录
# 创建目录
mkdir /data
#将来自manage01的共享存储/data 挂载至当前服务器的/data目录下
mount master01:/data /data -o proto=tcp -o nolock
设置开机自动挂载
键入vim /etc/fstab,在文档末尾添加
master01:/data /data nfs rw,auto,nofail,noatime,nolock,intr,tcp,actimeo=1800 0 0
查看挂载
df -h | grep data
# 有类似如下输出
master01:/data 79G 56M 75G 1% /data
测试挂载
# 例如在NFS服务端节点(其他节点也可以)写入一个测试文件
echo "hello nfs server" > /data/test.txt
cat /data/test.txt
# 在服务端节点或客户端节点均可以查看以下内容
hello nfs server
在共享文件系统中创建如下目录
# 创建home目录作为用户家目录的集合,可自定义
mkdir /data/home
# 创建software目录作为交互式应用的安装目录
mkdir /data/software
Munge安装
Munge是认证服务,实现本地或者远程主机进程的UID、GID验证。
需在每节点都有munge用户,且它们在各自节点上的UID和GID相同。
创建Munge用户
所有节点都创建Munge用户
groupadd -g 1108 munge
useradd -m -c "Munge Uid 'N' Gid Emporium" -d /var/lib/munge -u 1108 -g munge -s /sbin/nologin munge
生成熵池(entropy pool)
在master01节点上执行,安装rng工具,并采用/dev/urandom做熵源。
yum install -y rng-tools
rngd -r /dev/urandom
键入vim /usr/lib/systemd/system/rngd.service
修改如下
[service]
ExecStart=/sbin/rngd -f -r /dev/urandom
启动rngd
systemctl daemon-reload
systemctl start rngd
systemctl enable rngd
# systemctl status rngd 查看服务状态
部署Munge
在所有节点上都执行
yum install epel-release -y
yum install munge munge-libs munge-devel -y
在master01节点上创建全局使用的密钥。
/usr/sbin/create-munge-key -r
dd if=/dev/urandom bs=1 count=1024 > /etc/munge/munge.key
将密钥同步到所有其他节点
scp -p /etc/munge/munge.key root@compute01:/etc/munge/
scp -p /etc/munge/munge.key root@compute02:/etc/munge/
scp -p /etc/munge/munge.key root@compute03:/etc/munge/
scp -p /etc/munge/munge.key root@compute04:/etc/munge/
# 在所有节点上赋权
chown munge: /etc/munge/munge.key
chmod 400 /etc/munge/munge.key
所有节点执行启动命令
systemctl start munge
systemctl enable munge
# systemctl status munge 查看服务状态
测试Munge服务
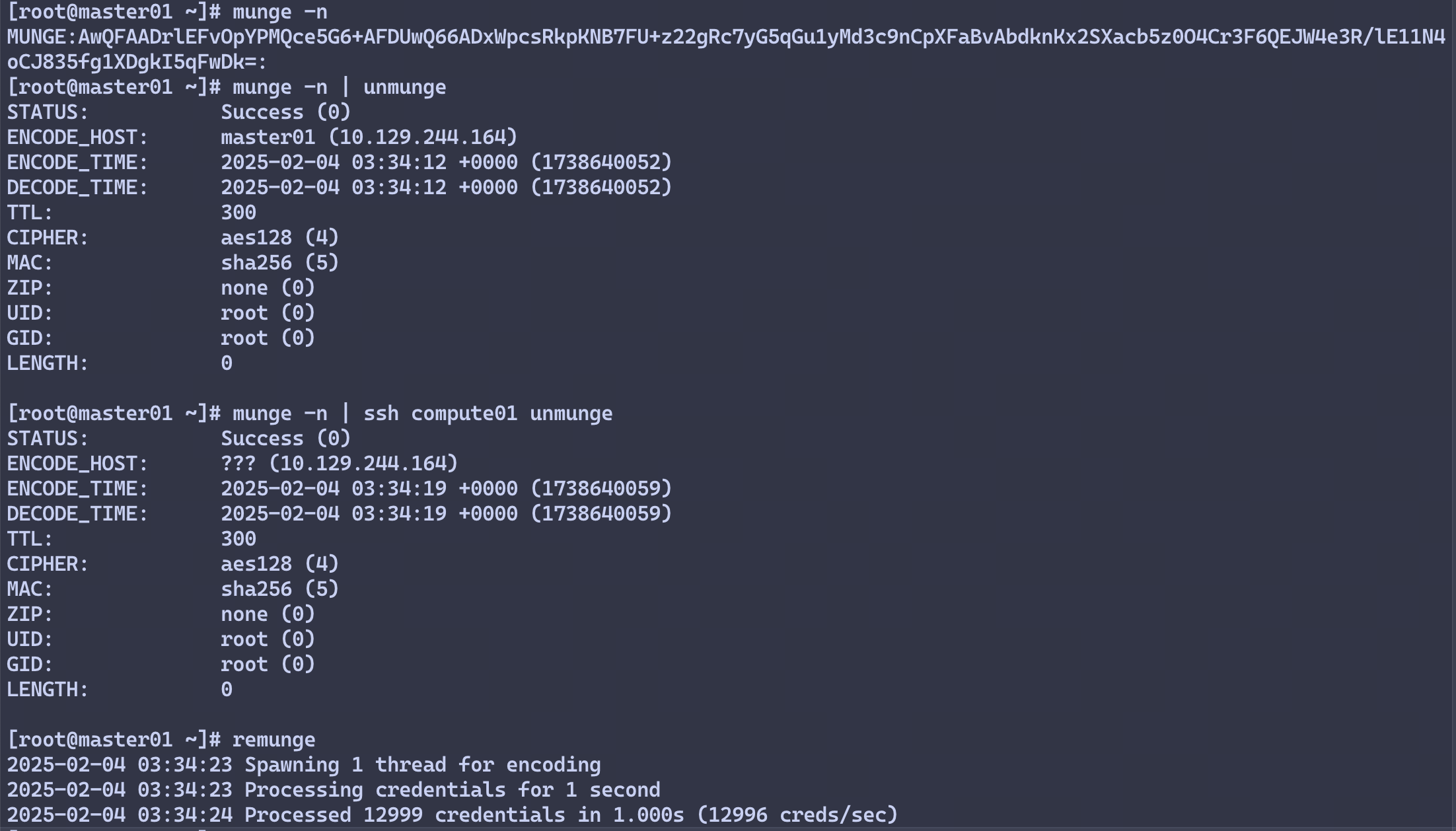
在master01节点执行
# 本地查看凭据
munge -n
# 本地解码
munge -n | unmunge
# 验证远程解码
munge -n | ssh compute01 unmunge
# munge凭证基准测试
remunge
示例输出
Slurm安装
安装mariadb
在master01节点安装mariadb,作为Slurm Accounting配置。 在master01执行
yum -y install mariadb-server
systemctl start mariadb
systemctl enable mariadb
ROOT_PASS=$(tr -dc A-Za-z0-9 </dev/urandom | head -c 16)
mysql -e "CREATE USER root IDENTIFIED BY '${ROOT_PASS}'"
mysql -uroot -p$ROOT_PASS -e 'create database slurm_acct_db'
创建slurm用户,并为其赋予slurm_acct_db数据库所有权。
mysql -uroot -p$ROOT_PASS
在数据库交互命令行中,键入
create user slurm;
grant all on slurm_acct_db.* TO 'slurm'@'localhost' identified by '123456' with grant option;
flush privileges;
exit
配置slurm
在所有节点执行
groupadd -g 1109 slurm
useradd -m -c "Slurm manager" -d /var/lib/slurm -u 1109 -g slurm -s /bin/bash slurm
安装slurm依赖
yum install gcc gcc-c++ readline-devel perl-ExtUtils-MakeMaker pam-devel rpm-build mysql-devel python3 -y
在master01节点制作RPM包 下载slurm
wget https://github.com/SchedMD/slurm/archive/refs/tags/slurm-24-11-1-1.tar.gz
安装rpmbuild,编译slurm,rpmbuild制作RPM包
yum install rpm-build -y
rpmbuild -ta --nodeps slurm-24.11.1.tar.bz2
制作完成后应在/root/rpmbuild/RPMS/x86_64目录下得到.rpm包。
在诸compute节点运行
mkdir -p /root/rpmbuild/RPMS/
将master01编译好的RPM包拷贝到其他节点
scp -r /root/rpmbuild/RPMS/x86_64 root@compute01:/root/rpmbuild/RPMS/x86_64
scp -r /root/rpmbuild/RPMS/x86_64 root@compute02:/root/rpmbuild/RPMS/x86_64
scp -r /root/rpmbuild/RPMS/x86_64 root@compute03:/root/rpmbuild/RPMS/x86_64
scp -r /root/rpmbuild/RPMS/x86_64 root@compute04:/root/rpmbuild/RPMS/x86_64
slurm安装与配置
在所有节点上都运行
cd /root/rpmbuild/RPMS/x86_64/
yum localinstall slurm-*
在master01节点上编辑slurm的配置文件。
cp /etc/slurm/cgroup.conf.example /etc/slurm/cgroup.conf
cp /etc/slurm/slurm.conf.example /etc/slurm/slurm.conf
cp /etc/slurm/slurmdbd.conf.example /etc/slurm/slurmdbd.conf
其中,slurm.conf和slurmdbd.conf可以参考文末附上的配置。
当然,推荐使用Slurm Configuration Tool来生成slurm.conf。
对于cgroup.conf,如果后续在compute节点上启动slurmd时遇到了cgroup/v2相关的错误,可以简单地在所有节点的/etc/slurm/cgroup.conf中添加这一行
CgroupPlugin=cgroup/v1
然后全部运行
mkdir -p /sys/fs/cgroup/freezer
mount -t cgroup -o freezer cgroup /sys/fs/cgroup/freezer
现在,复制配置文件到其他节点。
# slurmdbd.conf可不用复制,因为数据库运行在master01节点
scp -r /etc/slurm/*.conf root@compute01:/etc/slurm/
scp -r /etc/slurm/*.conf root@compute02:/etc/slurm/
scp -r /etc/slurm/*.conf root@compute03:/etc/slurm/
scp -r /etc/slurm/*.conf root@compute04:/etc/slurm/
在每一个节点上设置文件权限给slurm用户
mkdir /var/spool/slurmd
chown slurm: /var/spool/slurmd
mkdir /var/log/slurm
chown slurm: /var/log/slurm
mkdir /var/spool/slurmctld
chown slurm: /var/spool/slurmctld
启动服务
# 服务节点
systemctl start slurmdbd
systemctl enable slurmdbd
systemctl start slurmctld
systemctl enable slurmctld
# 所有节点
systemctl start slurmd
systemctl enable slurmd
# 通过 systemctl status ××× 查看服务状态,并确保个服务状态正常
可能的报错
# 1. 启动slurmdbd时报错(一):
slurmdbd: fatal: slurmdbd.conf file /etc/slurm/slurmdbd.conf should be 600 is 644 acc... others
# 解决方法
chmod 600 slurmdbd.conf
systemctl restart slurmdbd
# 2. 启动slurmdbd时报错(二):
slurmdbd: fatal: slurmdbd.conf not owned by SlurmUser root!=slurm
# 解决方法
chown slurm: /etc/slurm/slurmdbd.conf
systemctl restart slurmdbd
检查slurm集群
# 查看配置
scontrol show config
sinfo
scontrol show partition
scontrol show node
# 提交作业
srun -N2 hostname
scontrol show jobs
# 查看作业
squeue -a
配置QoS
# 查看已有的qos
sacctmgr show qos
# 创建low、high两个qos
sacctmgr create qos name=low
sacctmgr create qos name=high
# 给用户添加qos
sacctmgr modify user name={username} set qos=low,high,normal defaultQOS=low
Module安装
module给所有节点使用,因此放在NFS共享目录。在master01节点做这些事即可。
创建module安装目录
mkdir /data/software/module
TCL安装
module工具,依赖tcl工具,因此首先要安装tcl工具。
mkdir -p /data/software/module/tools/tcl
wget https://sourceforge.net/projects/tcl/files/Tcl/9.0.1/tcl9.0.1-src.tar.gz
tar -zxvf tcl9.0.1-src.tar.gz
cd tcl9.0.1/unix/
# 注意改前缀
./configure --prefix=/data/software/module/tools/tcl
make
make install
Module安装
mkdir -p /data/software/module/tools/modules
wget https://sourceforge.net/projects/modules/files/Modules/modules-5.5.0/modules-5.5.0.tar.gz
tar -zxvf modules-5.5.0.tar.gz
cd modules-5.5.0/
./configure --prefix=/data/software/module/tools/modules \
--with-tclsh=/data/software/module/tools/tcl/bin/tclsh9.0 \
--with-tclinclude=/data/software/module/tools/tcl/include \
--with-tcl=/data/software/module/tools/tcl/lib/
make
make install
配置Module
安装完成后,在/data/software/module/tools/modules/目录下,就有module工具了。不过在/usr/bin/目录下,是没有module命令的。
配置环境变量
source /data/software/module/tools/modules/init/profile.sh
或者将该行加入~/.bashrc,以便在每次终端连接时初始化module环境。
参考文档
slurm.conf
# slurm.conf file generated by configurator.html.
# Put this file on all nodes of your cluster.
# See the slurm.conf man page for more information.
#
ClusterName=CoHPC
SlurmctldHost=master01
#SlurmctldHost=
#
#DisableRootJobs=NO
#EnforcePartLimits=NO
#Epilog=
#EpilogSlurmctld=
#FirstJobId=1
#MaxJobId=67043328
#GresTypes=
#GroupUpdateForce=0
#GroupUpdateTime=600
#JobFileAppend=0
#JobRequeue=1
#JobSubmitPlugins=lua
#KillOnBadExit=0
#LaunchType=launch/slurm
#Licenses=foo*4,bar
#MailProg=/bin/mail
#MaxJobCount=10000
#MaxStepCount=40000
#MaxTasksPerNode=512
#MpiDefault=
#MpiParams=ports=#-#
#PluginDir=
#PlugStackConfig=
#PrivateData=jobs
ProctrackType=proctrack/cgroup
#Prolog=
#PrologFlags=
#PrologSlurmctld=
#PropagatePrioProcess=0
#PropagateResourceLimits=
#PropagateResourceLimitsExcept=
#RebootProgram=
ReturnToService=1
SlurmctldPidFile=/var/run/slurmctld.pid
SlurmctldPort=6817
SlurmdPidFile=/var/run/slurmd.pid
SlurmdPort=6818
SlurmdSpoolDir=/var/spool/slurmd
SlurmUser=slurm
#SlurmdUser=root
#SrunEpilog=
#SrunProlog=
StateSaveLocation=/var/spool/slurmctld
#SwitchType=
#TaskEpilog=
TaskPlugin=task/affinity
#TaskProlog=
#TopologyPlugin=topology/tree
#TmpFS=/tmp
#TrackWCKey=no
#TreeWidth=
#UnkillableStepProgram=
#UsePAM=0
#
#
# TIMERS
#BatchStartTimeout=10
#CompleteWait=0
#EpilogMsgTime=2000
#GetEnvTimeout=2
#HealthCheckInterval=0
#HealthCheckProgram=
InactiveLimit=0
KillWait=30
#MessageTimeout=10
#ResvOverRun=0
MinJobAge=300
#OverTimeLimit=0
SlurmctldTimeout=120
SlurmdTimeout=300
#UnkillableStepTimeout=60
#VSizeFactor=0
Waittime=0
#
#
# SCHEDULING
#DefMemPerCPU=0
#MaxMemPerCPU=0
#SchedulerTimeSlice=30
SchedulerType=sched/backfill
SelectType=select/cons_tres
#
#
# JOB PRIORITY
#PriorityFlags=
#PriorityType=priority/multifactor
#PriorityDecayHalfLife=
#PriorityCalcPeriod=
#PriorityFavorSmall=
#PriorityMaxAge=
#PriorityUsageResetPeriod=
#PriorityWeightAge=
#PriorityWeightFairshare=
#PriorityWeightJobSize=
#PriorityWeightPartition=
#PriorityWeightQOS=
#
#
# LOGGING AND ACCOUNTING
AccountingStorageEnforce=associations,limits,qos
AccountingStorageHost=master01
AccountingStoragePass=/var/run/munge/munge.socket.2
AccountingStoragePort=6819
AccountingStorageType=accounting_storage/slurmdbd
#AccountingStorageUser=
#AccountingStoreFlags=
JobCompHost=localhost
JobCompLoc=slurm_acct_db
#JobCompParams=
JobCompPass=123456
JobCompPort=3306
JobCompType=jobcomp/mysql
JobCompUser=slurm
JobContainerType=job_container/none
JobAcctGatherFrequency=30
JobAcctGatherType=jobacct_gather/linux
SlurmctldDebug=info
SlurmctldLogFile=/var/log/slurmctld.log
SlurmdDebug=info
SlurmdLogFile=/var/log/slurmd.log
#SlurmSchedLogFile=
#SlurmSchedLogLevel=
#DebugFlags=
#
#
# POWER SAVE SUPPORT FOR IDLE NODES (optional)
#SuspendProgram=
#ResumeProgram=
#SuspendTimeout=
#ResumeTimeout=
#ResumeRate=
#SuspendExcNodes=
#SuspendExcParts=
#SuspendRate=
#SuspendTime=
#
#
# COMPUTE NODES
NodeName=master01 CPUs=2 State=UNKNOWN
NodeName=compute0[1-4] CPUs=4 State=UNKNOWN
PartitionName=compute Nodes=ALL Default=YES MaxTime=INFINITE State=UP
比较重要的是最后这部分,master01有2个CPU,compute诸节点各有4个CPU。Accounting和Job诸选项应当按照自己的需求配置。
slurmdbd.conf
#
# slurmdbd.conf file.
#
# See the slurmdbd.conf man page for more information.
#
# Authentication info
AuthType=auth/munge #认证方式,该处采用munge进行认证
AuthInfo=/var/run/munge/munge.socket.2 #为了与slurmctld控制节点通信的其它认证信息
#
# slurmDBD info
DbdAddr=localhost #数据库节点名
DbdHost=localhost #数据库IP地址
SlurmUser=slurm #用户数据库操作的用户
DebugLevel=verbose #调试信息级别,quiet:无调试信息;fatal:仅严重错误信息;error:仅错误信息; info:错误与通常信息;verbose:错误和详细信息;debug:错误、详细和调试信息;debug2:错误、详细和更多调试信息;debug3:错误、详细和甚至更多调试信息;debug4:错误、详细和甚至更多调试信息;debug5:错误、详细和甚至更多调试信息。debug数字越大,信息越详细
LogFile=/var/log/slurm/slurmdbd.log #slurmdbd守护进程日志文件绝对路径
PidFile=/var/run/slurmdbd.pid #slurmdbd守护进程存储进程号文件绝对路径
#
# Database info
StorageType=accounting_storage/mysql #数据存储类型
StoragePass=123456 #存储数据库密码
StorageUser=slurm #存储数据库用户名
StorageLoc=slurm_acct_db #数据库名称